Фізична модель біномного розподілу. Біноміальний закон розподілу. Навіщо мені це треба
Розглянемо здійснення схеми Бернуллі, тобто. проводиться серія повторних незалежних випробувань, у кожному з яких дана подія А має одну і ту ж ймовірність, яка не залежить від номера випробування. І для кожного випробування є лише два результати:
1) подія А – успіх;
2) подія – неуспіх,
з постійними ймовірностями
Введемо до розгляду дискретну випадкову величину Х - «число появи події А при пвипробуваннях» і знайдемо закон розподілу цієї випадкової величини. Величина Х може набувати значення
Ймовірність ![]() того, що випадкову величину Х набуде значення x kзнаходиться за формулою Бернуллі
того, що випадкову величину Х набуде значення x kзнаходиться за формулою Бернуллі
Закон розподілу дискретної випадкової величини, який визначається формулою Бернуллі (1), називається біномним законом розподілу. Постійні п і р (q=1-p), що входять у формулу (1) називаються параметрами біномного розподілу.
Назва «біноміальний розподіл» пов'язана з тим, що права частина рівності (1) це загальний член розкладання бінома Ньютона, тобто.
(2)
А оскільки p+q=1, то права частина рівності (2) дорівнює 1
Це означає, що
 (4)
(4)
У рівності (3) перший член q nу правій частині означає ймовірність того, що в пвипробуваннях подія А не з'явиться жодного разу, другий член ![]() ймовірність того, що подія А з'явиться один раз, третій член - ймовірність, що подія А з'явиться двічі і нарешті останній член р п- ймовірність того, що подія А з'явиться рівно празів.
ймовірність того, що подія А з'явиться один раз, третій член - ймовірність, що подія А з'явиться двічі і нарешті останній член р п- ймовірність того, що подія А з'явиться рівно празів.
Біноміальний закон розподілу дискретної випадкової величини подають у вигляді таблиці:
| Х | 0 | 1 | … | k | … | n |
| Р | q n | … | … | р п |
Основні числові характеристики біномного розподілу:
1) математичне очікування ![]() (5)
(5)
2) дисперсія ![]() (6)
(6)
3) середнє квадратичне відхилення ![]() (7)
(7)
4) найімовірніше число поява події k 0- це число якому при заданому пвідповідає максимальна біномна ймовірність
При заданих пі рце число визначається нерівностями
![]() (8)
(8)
якщо число пр+рне є цілим, то k 0дорівнює цілій частині цього числа, якщо ж пр+р- ціле число, то k 0має два значення
Біноміальний закон розподілу ймовірностей застосовується в теорії стрільби, теорії та практики статистичного контролю якості продукції, теорії масового обслуговування, теорії надійності і т.д. Цей закон може застосовуватися у всіх випадках, коли є послідовність незалежних випробувань.
Приклад 1:Перевіркою якості встановлено, що з кожних 100 приладів немає дефектів 90 штук у середньому. Скласти біноміальний закон розподілу ймовірностей числа якісних приладів із придбаних навмання 4.
Рішення:Подія А - поява якого перевіряється це - «придбаний навмання прилад якісний». За умовою завдання основні параметри біномного розподілу:
Випадкова величина Х - число якісних приладів із взятих 4, означає значення Х -Знайдемо ймовірність значень Х за формулою (1):

Таким чином, закон розподілу величини Х - кількість якісних приладів із взятих 4:
| Х | 0 | 1 | 2 | 3 | 4 |
| Р | 0,0001 | 0,0036 | 0,0486 | 0,2916 | 0,6561 |
Для перевірки правильності побудови розподілу перевіримо, чому дорівнює сума ймовірностей
Відповідь:Закон розподілу
| Х | 0 | 1 | 2 | 3 | 4 |
| Р | 0,0001 | 0,0036 | 0,0486 | 0,2916 | 0,6561 |
Приклад 2:Застосовуваний метод лікування призводить до одужання у 95% випадків. П'ятеро хворих застосовували цей метод. Знайти найбільш імовірне число одужали, а так само числові характеристики випадкової величини Х - число одужали з 5 хворих, що застосовували даний метод.
Теорія ймовірності незримо є у нашому житті. Ми не звертаємо на це уваги, але кожна подія у нашому житті має ту чи іншу ймовірність. Беручи до уваги безліч варіантів розвитку подій, нам стає необхідним визначати найімовірніші і найменш ймовірні з них. Найбільш зручно аналізувати такі імовірнісні дані графічно. У цьому може допомогти розподіл. Біноміальне - одне з найлегших і найточніших.
Перш ніж перейти безпосередньо до математики та теорії ймовірності, розберемося з тим, хто ж перший вигадав такий вид розподілу та яка історія розвитку математичного апарату для цього поняття.
Історія
Поняття ймовірності відоме ще з давніх часів. Однак давні математики не надавали їй особливо значення і змогли закласти тільки основи для теорії, що згодом стала теорією ймовірності. Вони створили деякі комбінаторні методи, які сильно допомогли тим, хто пізніше створив та розвинув саму теорію.
У другій половині сімнадцятого століття почалося формування основних понять та методів теорії ймовірності. Було введено визначення випадкових величин, способи обчислення ймовірності простих та деяких складних незалежних та залежних подій. Продиктований такий інтерес до випадкових величин та ймовірностей був азартними іграми: кожна людина хотіла знати, які у неї шанси перемогти у грі.
Наступним етапом стало застосування теорії ймовірності методів математичного аналізу. Цим зайнялися визначні математики, такі як Лаплас, Гаусс, Пуассон і Бернуллі. Саме вони просунули цю галузь математики на новий рівень. Саме Джеймс Бернуллі відкрив біномний закон розподілу. До речі, як ми пізніше з'ясуємо, на основі цього відкриття було зроблено ще кілька, які дозволили створити закон нормального розподілуі ще багато інших.
Зараз, перш ніж почати описувати розподіл біномний, ми трохи освіжимо в пам'яті поняття теорії ймовірностей, напевно вже забуті зі шкільної лави.
Основи теорії ймовірностей
Розглянемо такі системи, в результаті дії яких можливі лише два результати: "успіх" і "не успіх". Це легко зрозуміти на прикладі: ми підкидаємо монетку, загадавши те, що випаде решка. Імовірності кожної з можливих подій (випаде решка – "успіх", випаде орел – "не успіх") дорівнюють 50 відсоткам при ідеальному балансуванні монети та відсутності інших факторів, які можуть вплинути на експеримент.
Це була найпростіша подія. Але бувають ще й складні системи, В яких виконуються послідовні дії, і ймовірності результатів цих дій відрізнятимуться. Наприклад, розглянемо таку систему: у коробці, вміст якої ми не можемо розглянути, лежать шість абсолютно однакових кульок, три пари синьої, червоної та білого квітів. Ми повинні дістати навмання кілька кульок. Відповідно, витягнувши першою одну з білих кульок, ми зменшимо в рази ймовірність того, що наступним нам теж трапиться біла кулька. Відбувається це тому, що змінюється кількість об'єктів у системі.
У наступному розділі розглянемо складніші математичні поняття, що впритул підводять нас до того, що означають слова "нормальний розподіл", "біноміальний розподіл" тощо.

Елементи математичної статистики
У статистиці, яка є однією з сфер застосування теорії ймовірностей, існує безліч прикладів, коли дані для аналізу дано не в явному вигляді. Тобто не в чисельному, а у вигляді поділу за ознаками, наприклад, за статевими. Для того, щоб застосувати до таких даних математичний апарат та зробити з отриманих результатів якісь висновки, потрібно перевести вихідні дані до числового формату. Як правило, для здійснення цього позитивного результату надають значення 1, а негативному - 0. Таким чином, ми отримуємо статистичні дані, які можна піддати аналізу за допомогою математичних методів.
Наступний крок у розумінні того, що таке біномний розподіл випадкової величини, - це визначення дисперсії випадкової величини та математичного очікування. Про це поговоримо у наступному розділі.

Математичне очікування
Насправді зрозуміти, що таке математичне очікування, нескладно. Розглянемо систему, де існує багато різних подій зі своїми різними ймовірностями. Математичним очікуванням називатиметься величина, що дорівнює сумі творів значень цих подій (а математичному вигляді, про який ми говорили в минулому розділі) на ймовірності їх здійснення.
Математичне очікування біномного розподілу розраховується за тією ж схемою: ми беремо значення випадкової величини, множимо його на ймовірність позитивного результату, а потім підсумовуємо отримані дані для всіх величин. Дуже зручно уявити ці дані графічно - краще сприймається різниця між математичними очікуваннями різних величин.
У наступному розділі ми розповімо вам трохи про інше поняття – дисперсію випадкової величини. Воно теж тісно пов'язане з таким поняттям, як біномний розподіл ймовірностей, і є його характеристикою.

Дисперсія біномного розподілу
Ця величина тісно пов'язана з попередньою та також характеризує розподіл статистичних даних. Вона являє собою середній квадрат відхилень значень від їхнього математичного очікування. Тобто дисперсія випадкової величини - це сума квадратів різниць між значенням випадкової величини та її математичним очікуванням, помножена на ймовірність цієї події.
Загалом це все, що нам потрібно знати про дисперсію для розуміння того, що таке біномне розподіл ймовірностей. Тепер перейдемо безпосередньо до нашої теми. А саме до того, що криється за таким на вигляд досить складним словосполученням "біноміальний закон розподілу".

Біноміальний розподіл
Розберемося для початку, чому ж цей розподіл биноміальний. Воно походить від слова "біном". Можливо, ви чули про біном Ньютона - таку формулу, за допомогою якої можна розкласти суму двох будь-яких чисел a і b будь-якою невід'ємною мірою n.
Як ви, напевно, вже здогадалися, формула бінома Ньютона та формула біномного розподілу – це практично однакові формули. За тим лише винятком, що друга має прикладне значення для конкретних величин, а перша - лише загальний математичний інструмент, застосування якого практично можуть бути різні.
Формули розподілу
Функція біномного розподілу може бути записана у вигляді суми наступних членів:
(n!/(n-k)!k!)*p k *q n-k
Тут n - число незалежних випадкових експериментів, p - число вдалих наслідків, q - число невдалих наслідків, k - номер експерименту (може приймати значення від 0 до n),! - позначення факторіалу, такої функції числа, значення якої дорівнює добутку всіх чисел, що йдуть до неї (наприклад, для числа 4: 4!=1*2*3*4=24).
Крім цього, функція біномного розподілу може бути записана у вигляді неповної бета-функції. Однак це вже складніше визначення, яке використовується лише при вирішенні складних статистичних завдань.
Біноміальний розподіл, приклади якого ми розглянули вище, - один із найпростіших видів розподілів у теорії ймовірностей. Існує також нормальний розподіл, що є одним із видів біномного. Воно використовується найчастіше, і найпростіше у розрахунках. Буває також розподіл Бернуллі, розподіл Пуассон, умовний розподіл. Всі вони характеризують графічно області ймовірності того чи іншого процесу за різних умов.
У наступному розділі розглянемо аспекти застосування цього математичного апарату в реальному житті. На перший погляд, звичайно, здається, що це чергова математична штука, яка, як завжди, не знаходить застосування у реальному житті, і взагалі не потрібна нікому, окрім самих математиків. Однак, це далеко не так. Адже всі види розподілів та їх графічні уявлення були створені виключно під практичні цілі, а не як забаганки вчених.

Застосування
Безумовно, найважливіше застосування розподілу знаходять у статистиці, адже там потрібен комплексний аналіз множини даних. Як показує практика, дуже багато масивів даних мають приблизно однакові розподіли величин: критичні області дуже низьких і дуже високих величин, як правило, містять менше елементів, ніж середні значення.
Аналіз великих масивів даних потрібно у статистиці. Він незамінний, наприклад, у фізичній хімії. У цій науці він використовується визначення багатьох величин, пов'язані з випадковими коливаннями і переміщеннями атомів і молекул.
У наступному розділі розберемося, наскільки важливим є застосування таких статистичних понять, як біномне розподіл випадкової величини в повсякденному життідля нас із вами.

Навіщо мені це треба?
Багато хто ставить собі таке питання, коли справа стосується математики. А між іншим, математика недарма називається царицею наук. Вона є основою фізики, хімії, біології, економіки, і в кожній з цих наук застосовується в тому числі і будь-який розподіл: чи це дискретний біномний розподіл, чи нормальний, не важливо. І якщо ми краще придивимося до навколишнього світу, то побачимо, що математика застосовується скрізь: у повсякденному житті, на роботі, і навіть людські відносини можна подати у вигляді статистичних даних і провести їх аналіз (так, до речі, і роблять ті, хто працюють у спеціальних організаціях, які займаються збиранням інформації).
Зараз поговоримо трохи про те, що ж робити, якщо вам потрібно знати на цю тему набагато більше, ніж те, що ми виклали в цій статті.
Та інформація, яку ми дали у цій статті, далеко не повна. Існує безліч нюансів щодо того, яку форму може набувати розподіл. Біноміальний розподіл, як ми вже з'ясували, є одним з основних видів, на якому ґрунтується вся математична статистика та теорія ймовірностей.
Якщо вам стало цікаво, чи у зв'язку з вашою роботою вам потрібно знати на цю тему набагато більше, потрібно буде вивчити спеціалізовану літературу. Почати слід з університетського курсу математичного аналізуі дійти до розділу теорії ймовірностей. Також знадобляться знання в області рядів, адже біномний розподіл ймовірностей - це ні що інше, як низка послідовних членів.
Висновок
Перш ніж закінчити статтю, ми хотіли б розповісти ще одну цікаву річ. Вона стосується безпосередньо теми нашої статті та всієї математики загалом.
Багато людей стверджують, що математика - марна наука, і ніщо з того, що вони проходили в школі, їм не знадобилося. Але знання ніколи не буває зайвим, і якщо вам щось не знадобилося в житті, значить, ви просто цього не пам'ятаєте. Якщо у вас є знання, вони можуть вам допомогти, але якщо їх немає, то допомоги від них чекати не доводиться.
Отже, ми розглянули поняття біномного розподілу і всі пов'язані з ним визначення і поговорили про те, як це застосовується в нашому з вами житті.
Звичайно, при обчисленні кумулятивної функції розподілу слід скористатися згаданим зв'язком біномного та бета-розподілу. Цей спосіб наперед краще безпосереднього підсумовування, коли n > 10.
У класичних підручниках зі статистики для отримання значень біномного розподілу часто рекомендують використовувати формули, що ґрунтуються на граничних теоремах (типу формули Муавра-Лапласа). Необхідно відмітити, що з суто обчислювальної точки зоруЦінність цих теорем близька до нуля, особливо зараз, коли практично на кожному столі стоїть потужний комп'ютер. Основний недолік наведених апроксимацій – їх зовсім недостатня точність при значеннях n, характерних більшості додатків. Не меншим недоліком є і відсутність скільки-небудь чітких рекомендацій щодо застосування тієї чи іншої апроксимації (у стандартних текстах наводяться лише асимптотичні формулювання, вони не супроводжуються оцінками точності і, отже, мало корисні). Я б сказав, що обидві формули придатні лише за n< 200 и для совсем грубых, ориентировочных расчетов, причем делаемых “вручную” с помощью статистических таблиц. А вот связь между биномиальным распределением и бета-распределением позволяет вычислять биномиальное распределение достаточно экономно.
Не розглядаю тут завдання пошуку квантилей: для дискретних розподілів вона тривіальна, а тих завданнях, де такі розподіли виникають, вона, зазвичай, і актуальна. Якщо ж кванти все-таки знадобляться, рекомендую так переформулювати завдання, щоб працювати з p-значеннями (спостереженими значущістю). Ось приклад: при реалізації деяких перебірних алгоритмів на кожному кроці потрібно перевіряти статистичну гіпотезу про біномну випадкову величину. Згідно з класичним підходом на кожному кроці потрібно обчислити статистику критерію та порівняти її значення з межею критичної множини. Оскільки, однак, алгоритм перебірний, доводиться визначати межу критичної множини щоразу заново (адже від кроку до кроку обсяг вибірки змінюється), що непродуктивно збільшує тимчасові витрати. Сучасний підхід рекомендує обчислювати спостережене значення і порівнювати її з довірчою ймовірністю, заощаджуючи на пошуку квантилей.
Тому в наведених нижче кодах відсутнє обчислення зворотної функції, натомість наведена функція rev_binomialDF , яка обчислює ймовірність p успіху в окремому випробуванні за заданою кількістю n випробувань, числу m успіхів у них і значення y ймовірності отримати ці m успіхів. При цьому використовується вищезгаданий зв'язок між біноміальним та бета-розподілом.
Фактично ця функція дозволяє отримувати межі довірчих інтервалів. Справді, припустимо, що у n біноміальних випробуваннях ми здобули m успіхів. Як відомо, ліва межа двостороннього довірчого інтервалу для параметра p з довірчим рівнем дорівнює 0, якщо m = 0, а є рішенням рівняння  . Аналогічно, права межа дорівнює 1, якщо m = n, а є рішенням рівняння
. Аналогічно, права межа дорівнює 1, якщо m = n, а є рішенням рівняння  . Звідси випливає, що для пошуку лівого кордону ми маємо вирішувати щодо рівняння
. Звідси випливає, що для пошуку лівого кордону ми маємо вирішувати щодо рівняння  , а для пошуку правої – рівняння
, а для пошуку правої – рівняння  . Вони і вирішуються у функціях binom_leftCI та binom_rightCI , що повертають верхню та нижню межі двостороннього довірчого інтервалу відповідно.
. Вони і вирішуються у функціях binom_leftCI та binom_rightCI , що повертають верхню та нижню межі двостороннього довірчого інтервалу відповідно.
Хочу зауважити, що якщо не потрібна зовсім неймовірна точність, то при досить великих n можна скористатися наступною апроксимацією [Б.Л. ван дер Варден, математична статистика. М: ІЛ, 1960, гол. 2, розд. 7]:  , де g - квантиль нормального розподілу Цінність цієї апроксимації в тому, що є дуже прості наближення, що дозволяють обчислювати квантил нормального розподілу (див. текст про обчислення нормального розподілу та відповідний розділ даного довідника). У моїй практиці (в основному, при n > 100) ця апроксимація давала приблизно 3-4 знаки, чого, як правило, цілком достатньо.
, де g - квантиль нормального розподілу Цінність цієї апроксимації в тому, що є дуже прості наближення, що дозволяють обчислювати квантил нормального розподілу (див. текст про обчислення нормального розподілу та відповідний розділ даного довідника). У моїй практиці (в основному, при n > 100) ця апроксимація давала приблизно 3-4 знаки, чого, як правило, цілком достатньо.
Для обчислень за допомогою нижченаведених кодів будуть потрібні файли betaDF.h , betaDF.cpp (див. розділ про бета-розподіл), а також logGamma.h , logGamma.cpp (див. додаток А). Ви також можете подивитися приклад використання функцій.
Файл binomialDF.h
| #ifndef __BINOMIAL_H__ #include "betaDF.h" double binomialDF(double trials, double successes, double p); /* * Нехай є "trials" незалежних спостережень * з ймовірністю "p" успіху в кожному. * Обчислюється ймовірність B(successes|trials,p) те, що число * успіхів укладено між 0 і "successes" (включно). */ double rev_binomialDF(double trials, double successes, double y); /* * Нехай відома ймовірність y настання не менше m успіхів * у trials випробуваннях схеми Бернуллі. Функція знаходить можливість p * успіху в окремому випробуванні. * * У обчисленнях використовується наступне співвідношення * * 1 - p = rev_Beta(trials-successes| successes+1, y). */ double binom_leftCI(double trials, double successes, double level); /* Нехай є "trials" незалежних спостережень * з ймовірністю "p" успіху в кожному * і кількість успіхів дорівнює "successes". * Обчислюється ліва межа двостороннього довірчого інтервалу * з рівнем значущості level. */ double binom_rightCI(double n, double successes, double level); /* Нехай є "trials" незалежних спостережень * з ймовірністю "p" успіху в кожному * і кількість успіхів дорівнює "successes". * Обчислюється правий кордон двостороннього довірчого інтервалу * з рівнем значущості level. */ #endif /* Ends #ifndef __BINOMIAL_H__ */ |
Файл binomialDF.cpp
| /************************************************* **********/ /* Біноміальний розподіл */ /************************************* ***************************/ #include |
Розглянемо Біноміальний розподіл, обчислимо його математичне очікування, дисперсію, моду. За допомогою функції MS EXCEL БІНОМ.РАСП() побудуємо графіки функції розподілу та щільності ймовірності. Зробимо оцінку параметра розподілу p, математичного очікування розподілу та стандартного відхилення. Також розглянемо розподіл Бернуллі.
Визначення. Нехай проводяться nвипробувань, у кожному з яких може відбутися лише дві події: подія «успіх» з ймовірністю p або подія «невдача» з ймовірністю q =1-p (так звана Схема Бернуллі,Bernoullitrials).
Імовірність отримання рівно x успіхів у цих n випробуваннях дорівнює:
Кількість успіхів у вибірці x є випадковою величиною, яка має Біноміальний розподіл(англ. Binomialdistribution) pі n – є параметрами цього розподілу.
Нагадаємо, що для застосування схеми Бернулліі відповідно Біноміального розподілу,повинні бути виконані такі умови:
- кожне випробування повинно мати рівно два результати, що умовно називають «успіхом» і «невдачею».
- результат кожного випробування повинен залежати від результатів попередніх випробувань (незалежність випробувань).
- ймовірність успіху p має бути постійною для всіх випробувань.
Біноміальний розподіл у MS EXCEL
У MS EXCEL, починаючи з версії 2010, для є функція БІНОМ.РАСП() , англійська назва - BINOM.DIST(), яка дозволяє обчислити ймовірність того, що у вибірці буде рівно х"Успіхів" (тобто. функцію щільності ймовірності p(x), див. формулу вище), і інтегральну функцію розподілу(ймовірність того, що у вибірці буде xабо менше "успіхів", включаючи 0).
До MS EXCEL 2010 EXCEL була функція БІНОМРАСП() , яка також дозволяє обчислити функцію розподілуі щільність імовірності p(x). БІНОМРАСП() залишено в MS EXCEL 2010 для сумісності.
У файлі прикладу наведено графіки густини розподілу ймовірностіі .

Біноміальний розподілмає позначення B (n ; p) .
Примітка: Для побудови інтегральної функції розподілуідеально підходить діаграма типу Графік, для густини розподілу – Гістограма з угрупуванням. Докладніше про побудову діаграм читайте статтю Основні типи діаграм.
Примітка: Для зручності написання формул у файлі прикладу створено Імена для параметрів Біноміального розподілу: n та p.

У прикладному файлі наведено різні розрахунки ймовірності за допомогою функцій MS EXCEL:
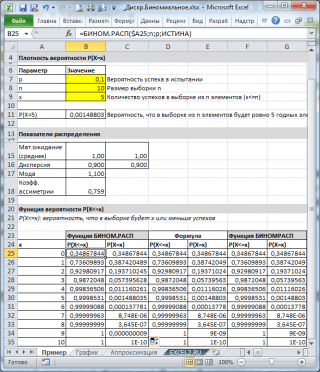
Як видно на картинці вище, передбачається, що:
- У нескінченній сукупності, з якої робиться вибірка, міститься 10% (або 0,1) придатних елементів (параметр p, Третій аргумент функції = БІНОМ.РАСП() )
- Щоб обчислити ймовірність того, що у вибірці з 10 елементів (параметр n, другий аргумент функції) буде рівно 5 придатних елементів (перший аргумент), потрібно записати формулу: =БІНОМ.РАСП(5; 10; 0,1; БРЕХНЯ)
- Останній, четвертий елемент, встановлений = БРЕХНЯ, тобто. повертається значення функції густини розподілу .
Якщо значення четвертого аргументу = ІСТИНА, то функція БІНОМ.РАСП() повертає значення інтегральної функції розподілуабо просто Функцію розподілу. У цьому випадку можна розрахувати ймовірність того, що у вибірці кількість придатних елементів буде з певного діапазону, наприклад, 2 або менше (включаючи 0).
Для цього потрібно записати формулу: = БІНОМ.РАСП(2; 10; 0,1; ІСТИНА)
Примітка: При нецілому значенні х, . Наприклад, такі формули повернуть одне й теж значення: =БІНОМ.РАСП( 2 ; 10; 0,1; ІСТИНА)=БІНОМ.РАСП( 2,9 ; 10; 0,1; ІСТИНА)
Примітка: У файлі прикладу щільність імовірностіі функція розподілутакож обчислені з використанням визначення та функції ЧИСЛКОМБ() .
Показники розподілу
У файл прикладу на аркуші Прикладє формули для розрахунку деяких показників розподілу:
- =n * p;
- (квадрату стандартного відхилення) = n * p * (1-p);
- = (n + 1) * p;
- =(1-2*p)*КОРІНЬ(n*p*(1-p)).
Виведемо формулу математичного очікуванняБіноміального розподілу, використовуючи Схему Бернуллі .
За визначенням випадкова величина Х в схемою Бернуллі(Bernoulli random variable) має функцію розподілу :

Цей розподіл називається розподіл Бернуллі .
Примітка : розподіл Бернуллі- окремий випадок Біноміального розподілуіз параметром n=1.
Згенеруємо 3 масиви по 100 чисел з різними ймовірностями успіху: 0,1; 0,5 та 0,9. Для цього у вікні Генерація випадкових чиселвстановимо такі параметри кожної ймовірності p:
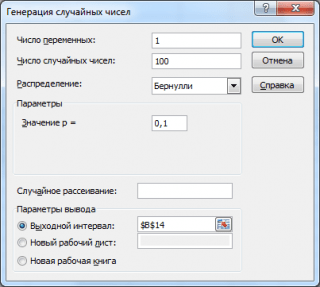
Примітка: Якщо встановити опцію Випадкове розсіювання (Random Seed), то можна вибрати певний випадковий набір згенерованих чисел. Наприклад, встановивши цю опцію =25 можна згенерувати різних комп'ютерах одні й самі набори випадкових чисел (якщо, звісно, інші параметри розподілу збігаються). Значення опції може приймати цілі значення від 1 до 32767. Назва опції Випадкове розсіюванняможе заплутати. Краще було б її перекласти як Номер набору з довільними числами .
У результаті матимемо 3 стовпці по 100 чисел, на підставі яких можна, наприклад, оцінити ймовірність успіху pза формулою: Число успіхів/100(Див. файл прикладу лист ГенераціяБернуллі).

Примітка: Для розподілу Бернулліз p = 0,5 можна використовувати формулу = ВИПАД МІЖ (0; 1), яка відповідає .
Генерація випадкових чисел. Біноміальний розподіл
Припустимо, що у вибірці виявилося 7 дефектних виробів. Це означає, що «дуже ймовірна» ситуація, що змінилася частка дефектних виробів pяка є характеристикою нашого виробничого процесу. Хоча така ситуація «дуже ймовірна», але існує ймовірність (альфа-ризик, помилка 1-го роду, «хибна тривога»), що все ж таки pзалишилася без змін, а збільшена кількість дефектних виробів зумовлена випадковістю вибірки.
Як видно на малюнку нижче, 7 – кількість дефектних виробів, яка припустима для процесу з p=0,21 при тому ж значенні Альфа. Це є ілюстрацією, що з перевищенні порогового значення дефектних виробів у вибірці, p«швидше за все» збільшилося. Фраза «швидше за все» означає, що існує лише 10% ймовірність (100%-90%) того, що відхилення частки дефектних виробів вище порогового викликане лише сучайними причинами.

Таким чином, перевищення порогової кількості дефектних виробів у вибірці може служити сигналом, що процес засмутився і став випускати б прольший відсоток бракованих виробів.
Примітка: До MS EXCEL 2010 у EXCEL була функція КРИТБІНОМ(), яка еквівалентна БІНОМ.ОБР(). КРИТБІНОМ залишена в MS EXCEL 2010 і вище для сумісності.
Зв'язок Біноміального розподілу з іншими розподілами
Якщо параметр nБіноміального розподілупрагне нескінченності, а pпрагне до 0, то в цьому випадку Біноміальний розподілможе бути апроксимовано. Можна сформулювати умови, коли наближення розподілом Пуассонапрацює добре:
- p(чим менше pі більше n, Тим наближення точніше);
- p >0,9 (враховуючи що q =1- p, обчислення в цьому випадку необхідно проводити через q(а хпотрібно замінити на n - x). Отже, чим менше qі більше n, Тим наближення точніше).
При 0,110 Біноміальний розподілможна апроксимувати.
В свою чергу, Біноміальний розподілможе бути хорошим наближенням , коли розмір сукупності N Гіпергеометричного розподілунабагато більше розміру вибірки n (тобто, N>>n або n/N Детальніше про зв'язок вищевказаних розподілів, можна прочитати в статті . Там же наведені приклади апроксимації, і пояснені умови, коли вона можлива і з якою точністю.
ПОРАДА: Про інші розподіли MS EXCEL можна прочитати у статті .
- (binomial distribution) Розподіл, що дозволяє розрахувати ймовірність настання якоїсь випадкової події, отриманої в результаті спостережень ряду незалежних подій, якщо ймовірність наступу, що становлять його елементарні… Економічний словник
- (розподіл Бернуллі) розподіл ймовірностей числа появ певної події при повторних незалежних випробуваннях, якщо ймовірність появи цієї події в кожному випробуванні дорівнює p(0 p 1). Саме число? появ цієї події є… … Великий Енциклопедичний словник
біномний розподіл- - Тематики електрозв'язок, основні поняття EN binomial distribution …
- (розподіл Бернуллі), розподіл ймовірностей числа появ певної події при повторних незалежних випробуваннях, якщо ймовірність появи цієї події в кожному випробуванні дорівнює р (0≤р≤1). Саме, кількість μ появи цієї події… … Енциклопедичний словник
біномний розподіл– 1.49. Біноміальний розподіл Розподіл ймовірностей дискретної випадкової величини X, що приймає будь-які цілі значення від 0 до n, таке, що при х = 0, 1, 2, ..., n і параметрах n = 1, 2, ... і 0< p < 1, где Источник … Словник-довідник термінів нормативно-технічної документації
Розподіл Бернуллі, розподіл ймовірностей випадкової величини X, що приймає цілі значення з ймовірностями відповідно (біноміальний коефіцієнт; р параметр Б. р., наз. ймовірністю позитивного результату, що приймає значення … Математична енциклопедія
Розподіл ймовірностей кількості появ певної події при повторних незалежних випробуваннях. Якщо при кожному випробуванні ймовірність появи події дорівнює р, причому 0 ≤ p ≤ 1, то μ появ цієї події при n незалежних… … Велика Радянська Енциклопедія
- (розподіл Бернуллі), розподіл ймовірностей числа появ нек рого події при повторних незалежних випробуваннях, якщо ймовірність появи цієї події в кожному випробуванні дорівнює р (0<или = p < или = 1). Именно, число м появлений … Природознавство. Енциклопедичний словник
Біноміальний розподіл ймовірностей- (binomial distribution) Розподіл, який спостерігається у випадках, коли результат кожного незалежного експерименту (статистичного спостереження) приймає одне з двох можливих значень: перемога чи поразка, включення чи виняток, плюс чи … Економіко-математичний словник
біномне розподіл ймовірностей- Розподіл, який спостерігається у випадках, коли результат кожного незалежного експерименту (статистичного спостереження) набуває одного з двох можливих значень: перемога чи поразка, включення чи виняток, плюс чи мінус, 0 чи 1. Тобто… … Довідник технічного перекладача
Книги
- Теорія ймовірностей та математична статистика у завданнях. Більше 360 завдань та вправ, Д. А. Борзих. У запропонованому посібнику містяться завдання різного рівня складності. Проте основний акцент зроблено на завдання середньої складності. Це зроблено навмисно для того, щоб спонукати студентів до…
- Теорія ймовірностей та математична статистика у завданнях Більше 360 завдань та вправ, Борзих Д.. У запропонованому посібнику містяться завдання різного рівня складності. Проте основний акцент зроблено на завдання середньої складності. Це зроблено навмисно для того, щоб спонукати студентів до…
